Instagram System Design
Introduction to the System
Let's design a photo-sharing service like Instagram, where users can upload photos to share them with other users. Similar Services: Flickr, Picasa.
1. What is Instagram?
Instagram is a social networking service that enables its users to upload and share their photos and videos with other users.
2. Requirements and Goals of the System
Will be focusing on the functional and non-functional requirements of the system. Also we can define what actual features from the actual instagram are not in scope to minimize the effort.
3. Some Design Considerations
What would be the feasible features and constraints of the system? Some of the consideration that we can think of that makes the system feasible to design in the given time period.
4. Capacity Estimation and Constraints
Discussion about the traffic and storage that the system would be using. This will also be categorized on the basis of different timelines. For e.g. what is the overall space needed for the system to be up and running for 10 years.
5. High Level System Design
Discussion about the high level design of instagram system. What are the services involved in the system and interaction between them along with the relationship with the db.
6. Database Schema
What are the tables that are needed in the system? What are the columns in each table? What are the constraints on the columns? Which db to choose for the given system design?
7. Data Size Estimation
This section will be specifically focused on, What is the data size of the db? What is the data size of the images? What is the data size of the videos? What is the size of the user that will be stored in the db, how many users can we support in the system?
8. Component Design
Considering each component of the system, what are the services that are involved and how are they related to each other? What are the dependencies between the services? What are the dependencies between the services and the db?
9. Reliability and Redundancy
Discussing whether the system is reliable or not meaning if I upload anything to the system and if it is lost or not. What are the ways to make the system reliable? Discussion related to what if one of the server fails then will the whole system collapse?
10. Data Sharding
Creating backup of the database and partitioning the database so that the data is not lost if one of the server fails. This also helps in the faster retrieval of the data and hence reducing the overall latency of the system.
11. Ranking and News Feed Generation
How the home page of the application will be behaving and what are the initial assumptions and methods that are taken in consideration for the same. What are the different approaches that are taken to generate the news feed?
12. News Feed Creation with Sharded Data
As we are dealing with the distributed system how will the main feature of the system will be behaving with the database and how will the system be interacting with the database. The process includes fetching of the latest photos uploaded from the people who are following the user.
13. Cache and Load balancing
Our service would need a massive-scale photo delivery system to serve globally distributed users. Our service should push its content closer to the user using a large number of geographically distributed photo cache servers and use CDNs.
14. What Powers Instagram - Blog Post from Instagram
One of the questions we always get asked at meet-ups and conversations with other engineers is, "what's your stack?" We thought it would be fun to give a sense of all the systems that power Instagram, at a high-level; you can look forward to more in-depth descriptions of some of these systems in the future.
1. What is Instagram?
Instagram is a social networking service that enables its users to upload and share their photos and videos with other users. Instagram users can choose to share information either publicly or privately. Anything shared publicly can be seen by any other user, whereas privately shared content can only be accessed by the specified set of people. Instagram also enables its users to share through many other social networking platforms, such as Facebook, Twitter, Flickr, and Tumblr.
We plan to design a simpler version of Instagram for this design problem, where a user can share photos and follow other users. The 'News Feed' for each user will consist of top photos of all the people the user follows.
2. Requirements and Goals of the System
Functional Requirements
- Users should be able to upload/download/view photos.
- Users can perform searches based on photo/video titles.
- Users can follow other users.
- The system should generate and display a user's News Feed consisting of top photos from all the people the user follows.
Non-Functional Requirements
- Our service needs to be highly available.
- The acceptable latency of the system is 200ms for News Feed generation.
- Consistency can take a hit (in the interest of availability) if a user doesn't see a photo for a while; it should be fine.
- The system should be highly reliable; any uploaded photo or video should never be lost.
3. Some Design Consideration
The system would be read-heavy, so we will focus on building a system that can retrieve photos quickly.
- Practically, users can upload as many photos as they like; therefore, efficient management of storage should be a crucial factor in designing this system.
- Low latency is expected while viewing photos.
- Data should be 100% reliable. If a user uploads a photo, the system will guarantee that it will never be lost.
4. Capacity Estimation and Constraints
- Let's assume we have 500M total users, with 1M daily active users.
- 2M new photos every day, 23 new photos every second.
- Average photo file size => 200KB
- Total space required for 1 day of photos 2M * 200KB => 400 GB
- Total space required for 10 years: 400GB 365 (days a year) 10 (years) ~= 1425TB
5. High Level System Design
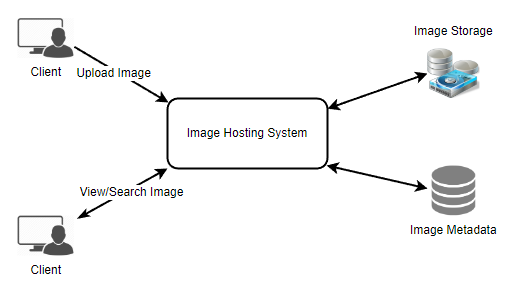
At a high-level, we need to support two scenarios, one to upload photos and the other to view/search photos. Our service would need some object storage servers to store photos and some database servers to store metadata information about the photos.
6. Database Schema
We need to store data about users, their uploaded photos, and the people they follow. The Photo table will store all data related to a photo; we need to have an index on (PhotoID, CreationDate) since we need to fetch recent photos first.
Table: Photo
| Column | Type |
|---|---|
| PhotoID | INT |
| UserID | INT |
| PhotoURL | VARCHAR(255) |
| PhotoLatitude | DOUBLE |
| PhotoLongitude | DOUBLE |
| UserLatitude | DOUBLE |
| UserLongitude | DOUBLE |
| CreationDate | DATETIME |
Table: User
| Column | Type |
|---|---|
| UserID | INT |
| UserName | VARCHAR(255) |
| UserPassword | VARCHAR(255) |
| UserLatitude | DOUBLE |
| UserLongitude | DOUBLE |
| UserCreationDate | DATETIME |
| UserLastLoginDate | DATETIME |
We can store the above schema in a distributed key-value store to enjoy the benefits offered by NoSQL. All the metadata related to photos can go to a table where the 'key' would be the 'PhotoID' and the 'value' would be an object containing PhotoLocation, UserLocation, CreationTimestamp, etc.
NoSQL stores, in general, always maintain a certain number of replicas to offer reliability. Also, in such data stores, deletes don't get applied instantly; data is retained for certain days (to support undeleting) before getting removed from the system permanently.
Why choose NoSQL?
NoSql makes more sense to me because there are billions of videos on youtube and scaling relational database is hard (vertical scaling) and it will reach its limitation.
Whereas NoSql database like Cassandra are specifically designed with Big Data in mind and they are easily scalable. We need to come up with the right schema for tables so that queries which we run on Cassandra are efficient. Cassandra is write optimized not read.
For example Here for storing Metadata and user information we should answer this question:
- Schema Might change in future a lot ? - ✅ (NoSQL) | ❌ (SQL)
- Do we care about the constituency about the likes and dislikes? - ✅ (SQL) | ❌ (NoSQL)
- Do we have lot of relations in our DB: ✅ (SQL) | ❌ (NoSQL)
- Are we going to do lots of Joins operation on data : ✅ (SQL) | ❌ (NoSQL)
7. Data Size Estimation
User Data Size Per Record/Row
Assuming each "int" and "dateTime" is four bytes, each row in the User's table will be of 68 bytes:
UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + DateOfBirth (4 bytes) + CreationDate (4 bytes) + LastLogin (4 bytes) = 68 bytes If we have 500 million users, we will need 32GB of total storage.
500 million \* 68 ~= 32GBPhoto Data Size Per Record/Row
Each row in Photo's table will be of 284 bytes:
PhotoID (4 bytes) + UserID (4 bytes) + PhotoPath (256 bytes) + PhotoLatitude (4 bytes) + PhotoLongitude(4 bytes) + UserLatitude (4 bytes) + UserLongitude (4 bytes) + CreationDate (4 bytes) = 284 bytes If 2M new photos get uploaded every day, we will need 0.5GB of storage for one day:
2M * 284 bytes ~= 0.5GB per day For 10 years we will need 1.88TB of storage.
UserFollow Data Size Per Record/Row
Overall/Total Data Size Per Record/Row
Total space required for all tables for 10 years will be 3.7TB:
32GB + 1.88TB + 1.82TB ~= 3.7TB8. Component Design
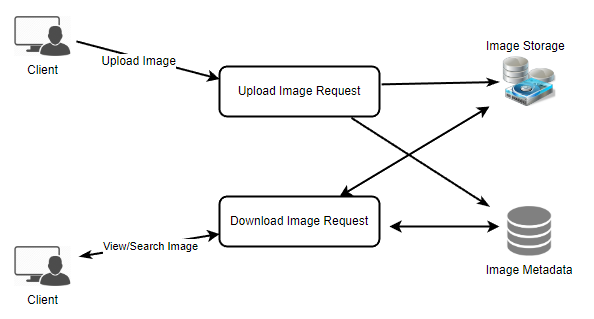
Photo uploads (or writes) can be slow as they have to go to the disk, whereas reads will be faster, especially if they are being served from cache.
Uploading users can consume all the available connections, as uploading is a slow process. This means that 'reads' cannot be served if the system gets busy with all the 'write' requests. We should keep in mind that web servers have a connection limit before designing our system. If we assume that a web server can have a maximum of 500 connections at any time, then it can't have more than 500 concurrent uploads or reads.
To handle this bottleneck, we can split reads and writes into separate services. We will have dedicated servers for reads and different servers for writes to ensure that uploads don't hog the system.
Separating photos' read and write requests will also allow us to scale and optimize each of these operations independently.
9. Reliability and Redundancy
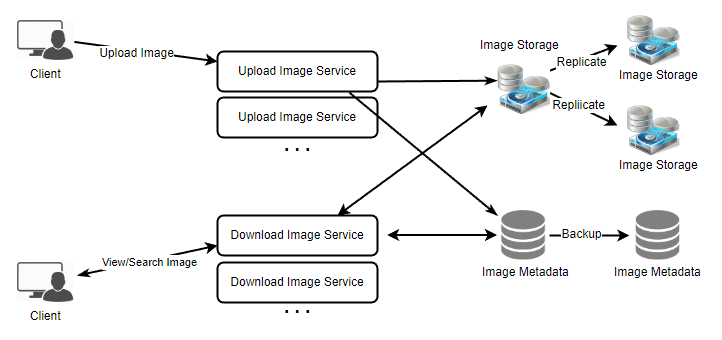
Losing files is not an option for our service. Therefore, we will store multiple copies of each file so that if one storage server dies, we can retrieve the photo from the other copy present on a different storage server.
This same principle also applies to other components of the system. If we want to have high availability of the system, we need to have multiple replicas of services running in the system so that even if a few services die down, the system remains available and running. Redundancy removes the single point of failure in the system.
If only one instance of a service is required to run at any point, we can run a redundant secondary copy of the service that is not serving any traffic, but it can take control after the failover when the primary has a problem.
Creating redundancy in a system can remove single points of failure and provide a backup or spare functionality if needed in a crisis. For example, if there are two instances of the same service running in production and one fails or degrades, the system can failover to the healthy copy. Failover can happen automatically or require manual intervention.
10. Data Sharding
Partitioning based on UserID
Let's assume we shard based on the 'UserID' so that we can keep all photos of a user on the same shard. If one DB shard is 1TB, we will need four shards to store 3.7TB of data. Let's assume, for better performance and scalability, we keep 10 shards.
So we'll find the shard number by UserID % 10 and then store the data there. To uniquely identify any photo in our system, we can append the shard number with each PhotoID.
How can we generate PhotoIDs?
Each DB shard can have its own auto-increment sequence for PhotoIDs, and since we will append ShardID with each PhotoID, it will make it unique throughout our system.
What are the different issues with this partitioning scheme?
- How would we handle hot users? Several people follow such hot users, and a lot of other people see any photo they upload.
- Some users will have a lot of photos compared to others, thus making a non-uniform distribution of storage.
- What if we cannot store all pictures of a user on one shard? If we distribute photos of a user onto multiple shards, will it cause higher latencies?
- Storing all photos of a user on one shard can cause issues like unavailability of all of the user's data if that shard is down or higher latency if it is serving high load etc.
Partitioning based on PhotoID
If we can generate unique PhotoIDs first and then find a shard number through “PhotoID % 10”, the above problems will have been solved. We would not need to append ShardID with PhotoID in this case, as PhotoID will itself be unique throughout the system.
How can we generate PhotoIDs?
Here, we cannot have an auto-incrementing sequence in each shard to define PhotoID because we need to know PhotoID first to find the shard where it will be stored. One solution could be that we dedicate a separate database instance to generate auto-incrementing IDs. If our PhotoID can fit into 64 bits, we can define a table containing only a 64 bit ID field.
So whenever we would like to add a photo in our system, we can insert a new row in this table and take that ID to be our PhotoID of the new photo.
Wouldn't this key generating DB be a single point of failure?
Yes, it would be. A workaround for that could be to define two such databases, one generating even-numbered IDs and the other odd-numbered. We can put a load balancer in front of both of these databases to round-robin between them and to deal with downtime. Both these servers could be out of sync, with one generating more keys than the other, but this will not cause any issue in our system.
We can extend this design by defining separate ID tables for Users, Photo-Comments, or other objects present in our system.
How can we plan for the future growth of our system?
We can have a large number of logical partitions to accommodate future data growth, such that in the beginning, multiple logical partitions reside on a single physical database server. Since each database server can have multiple database instances running on it, we can have separate databases for each logical partition on any server.
So whenever we feel that a particular database server has a lot of data, we can migrate some logical partitions from it to another server. We can maintain a config file (or a separate database) that can map our logical partitions to database servers; this will enable us to move partitions around easily. Whenever we want to move a partition, we only have to update the config file to announce the change.
11. Ranking and News Feed Generation
Workflow for Ranking
To create the News Feed for any given user, we need to fetch the latest, most popular, and relevant photos of the people the user follows.
For simplicity, let's assume we need to fetch the top 100 photos for a user's News Feed. Our application server will first get a list of people the user follows and then fetch metadata info of each user's latest 100 photos. In the final step, the server will submit all these photos to our ranking algorithm, which will determine the top 100 photos (based on recency, likeness, etc.) and return them to the user.
Pre-generating the News Feed
A possible problem with this approach would be higher latency as we have to query multiple tables and perform sorting/merging/ranking on the results. To improve the efficiency, we can pre-generate the News Feed and store it in a separate table.
We can have dedicated servers that are continuously generating users' News Feeds and storing them in a ‘UserNewsFeed' table. So whenever any user needs the latest photos for their News-Feed, we will simply query this table and return the results to the user.
Whenever these servers need to generate the News Feed of a user, they will first query the UserNewsFeed table to find the last time the News Feed was generated for that user. Then, new News-Feed data will be generated from that time onwards (following the steps mentioned above).
What are the different approaches for sending News Feed contents to the users?
1. Pull:
Clients can pull the News-Feed contents from the server at a regular interval or manually whenever they need it. Possible problems with this approach are a) New data might not be shown to the users until clients issue a pull request b) Most of the time, pull requests will result in an empty response if there is no new data.
2. Push:
Servers can push new data to the users as soon as it is available. To efficiently manage this, users have to maintain a Long Poll request with the server for receiving the updates. A possible problem with this approach is a user who follows a lot of people or a celebrity user who has millions of followers; in this case, the server has to push updates quite frequently.
3. Hybrid:
We can adopt a hybrid approach. We can move all the users who have a high number of followers to a pull-based model and only push data to those who have a few hundred (or thousand) follows. Another approach could be that the server pushes updates to all the users not more than a certain frequency and letting users with a lot of updates to pull data regularly.
12. News Feed Creation with Sharded Data
One of the most important requirements to create the News Feed for any given user is to fetch the latest photos from all people the user follows. For this, we need to have a mechanism to sort photos on their time of creation. To efficiently do this, we can make photo creation time part of the PhotoID. As we will have a primary index on PhotoID, it will be quite quick to find the latest PhotoIDs.
We can use epoch time for this. Let's say our PhotoID will have two parts; the first part will be representing epoch time, and the second part will be an auto-incrementing sequence. So to make a new PhotoID, we can take the current epoch time and append an auto-incrementing ID from our key-generating DB. We can figure out the shard number from this PhotoID ( PhotoID % 10) and store the photo there.
What could be the size of our PhotoID?
Let's say our epoch time starts today; how many bits we would need to store the number of seconds for the next 50 years?
86400 sec/day _ 365 (days a year) _ 50 (years) => 1.6 billion secondsWe would need 31 bits to store this number. Since, on average, we are expecting 23 new photos per second, we can allocate 9 additional bits to store the auto-incremented sequence. So every second, we can store (2^9 => 512) (2^9=>512) new photos. We are allocating 9 bits for the sequence number which is more than what we require; we are doing this to get a full byte number (as 40 bits = 5 bytes). We can reset our auto-incrementing sequence every second.
13. Cache and Load balancing
Our service would need a massive-scale photo delivery system to serve globally distributed users. Our service should push its content closer to the user using a large number of geographically distributed photo cache servers and use CDNs.
We can introduce a cache for metadata servers to cache hot database rows. We can use Memcache to cache the data, and Application servers before hitting the database can quickly check if the cache has desired rows. Least Recently Used (LRU) can be a reasonable cache eviction policy for our system. Under this policy, we discard the least recently viewed row first.
How can we build a more intelligent cache?
If we go with the eighty-twenty rule, i.e., 20% of daily read volume for photos is generating 80% of the traffic, which means that certain photos are so popular that most people read them. This dictates that we can try caching 20% of the daily read volume of photos and metadata.
14. What Powers Instagram (Optional)
One of the questions we always get asked at meet-ups and conversations with other engineers is, “what's your stack?” We thought it would be fun to give a sense of all the systems that power Instagram, at a high-level; you can look forward to more in-depth descriptions of some of these systems in the future.
This is how our system has evolved in the just-over-1-year that we've been live, and while there are parts we're always re-working, this is a glimpse of how a startup with a small engineering team can scale to our 14 million+ users in a little over a year. Our core principles when choosing a system are:
- Keep it very simple
- Don't re-invent the wheel
- Go with proven and solid technologies when you can
OS / Hosting
We run Ubuntu Linux 11.04 (“Natty Narwhal”) on Amazon EC2. We've found previous versions of Ubuntu had all sorts of unpredictable freezing episodes on EC2 under high traffic, but Natty has been solid.
We've only got 3 engineers, and our needs are still evolving, so self-hosting isn't an option we've explored too deeply yet, though is something we may revisit in the future given the unparalleled growth in usage.
Load Balancing
Every request to Instagram servers goes through load balancing machines; we used to run 2 nginx machines and DNS Round-Robin between them. The downside of this approach is the time it takes for DNS to update in case one of the machines needs to get decomissioned.
Recently, we moved to using Amazon's Elastic Load Balancer, with 3 NGINX instances behind it that can be swapped in and out (and are automatically taken out of rotation if they fail a health check). We also terminate our SSL at the ELB level, which lessens the CPU load on nginx. We use Amazon's Route53 for DNS, which they've recently added a pretty good GUI tool for in the AWS console.
Application Servers
Next up comes the application servers that handle our requests. We run Django on Amazon High-CPU Extra-Large machines, and as our usage grows we've gone from just a few of these machines to over 25 of them (luckily, this is one area that's easy to horizontally scale as they are stateless).
We've found that our particular work-load is very CPU-bound rather than memory-bound, so the High-CPU Extra-Large instance type provides the right balance of memory and CPU.
We use http://gunicorn.org/ as our WSGI server; we used to use mod_wsgi and Apache, but found Gunicorn was much easier to configure, and less CPU-intensive. To run commands on many instances at once (like deploying code), we use Fabric, which recently added a useful parallel mode so that deploys take a matter of seconds.
Task Queue & Push Notifications
When a user decides to share out an Instagram photo to Twitter or Facebook, or when we need to notify one of our Real-time subscribers of a new photo posted, we push that task into Gearman, a task queue system originally written at Danga.
Doing it asynchronously through the task queue means that media uploads can finish quickly, while the ‘heavy lifting' can run in the background. We have about 200 workers (all written in Python) consuming the task queue at any given time, split between the services we share to. We also do our feed fan-out in Gearman, so posting is as responsive for a new user as it is for a user with many followers.
For doing push notifications, the most cost-effective solution we found was github.com/samuraisam/pyapns, an open-source Twisted service that has handled over a billion push notifications for us, and has been rock-solid.
Data storage
Most of our data (users, photo metadata, tags, etc) lives in PostgreSQL; we've previously written about how we shard across our different Postgres instances. Our main shard cluster involves 12 Quadruple Extra-Large memory instances (and twelve replicas in a different zone.)
We've found that Amazon's network disk system (EBS) doesn't support enough disk seeks per second, so having all of our working set in memory is extremely important. To get reasonable IO performance, we set up our EBS drives in a software RAID using mdadm.
As a quick tip, we've found that vmtouch is a fantastic tool for managing what data is in memory, especially when failing over from one machine to another where there is no active memory profile already.
All of our PostgreSQL instances run in a master-replica setup using Streaming Replication, and we use EBS snap-shotting to take frequent backups of our systems. We use XFS as our file system, which lets us freeze & unfreeze the RAID arrays when snap-shotting, in order to guarantee a consistent snapshot (our original inspiration came from ec2-consistent-snapshot. To get streaming replication started, our favorite tool is repmgr by the folks at 2ndQuadrant.
To connect to our databases from our app servers, we made early on that had a huge impact on performance was using Pgbouncer to pool our connections to PostgreSQL. We found Christophe Pettus's blog to be a great resource for Django, PostgreSQL and Pgbouncer tips.
The photos themselves go straight to Amazon S3, which currently stores several terabytes of photo data for us. We use Amazon CloudFront as our CDN, which helps with image load times from users around the world (like in Japan, our second most-popular country).
We also use Redis extensively; it powers our main feed, our activity feed, our sessions system (here's our Django session backend), and other related systems. All of Redis' data needs to fit in memory, so we end up running several Quadruple Extra-Large Memory instances for Redis, too, and occasionally shard across a few Redis instances for any given subsystem.
We run Redis in a master-replica setup, and have the replicas constantly saving the DB out to disk, and finally use EBS snapshots to backup those DB dumps (we found that dumping the DB on the master was too taxing). Since Redis allows writes to its replicas, it makes for very easy online failover to a new Redis machine, without requiring any downtime.
We run Redis in a master-replica setup, and have the replicas constantly saving the DB out to disk, and finally use EBS snapshots to backup those DB dumps (we found that dumping the DB on the master was too taxing). Since Redis allows writes to its replicas, it makes for very easy online failover to a new Redis machine, without requiring any downtime.
Monitoring
With 100+ instances, it's important to keep on top of what's going on across the board. We use Munin to graph metrics across all of our system, and also alert us if anything is outside of its normal range. We write a lot of custom Munin plugins, building on top of Python-Munin, to graph metrics that aren't system-level (for example, sign-ups per minute, photos posted per second, etc).
We use Pingdom for external monitoring of the service, and PagerDuty for handling notifications and incidents.
For Python error reporting, we use Sentry, an awesome open-source Django app written by the folks at Disqus. At any given time, we can sign-on and see what errors are happening across our system, in real time.